Why is Go so darn fast?
Reza A. Alipour / December 26, 2022
6 min read
Go is famous for being fast. In fact, Go's outstanding performance manifests the best when used in concurrent tasks. While many facets enable Go to perform well in concurrent tasks, there is one particular ingenious in Go that is of great importance. Go helps the underlying OS and takes responsibility for some of the heavy lifting.
Disclaimer: This post is not meant to be literally true with respect to every detail, nor does it explain everything relevant to the topic. It's just an attempt to simplify a thorough concept.
To understand the extent of this help, a short context is in order. There are quite a few hardware-level CPU cores on a single PC, e.g. 8 logical CPU cores on an Intel Core-i7 processor. However, when you boot up a PC, there are probably hundreds of processes that run simultaneously. How is that possible? Every prominent OS has a task scheduler is tasked to allocate the processor's resources to threads. A thread is a path of execution containing an ordered set of machine instructions and each process has one or more of them.
Generally, a thread can be in three different states: It's in Executing when it's currently running on a CPU core. It's in Runnable state when it's ready to be executed, and it's in a Wating state when it is stopped, waiting for something to happen, e.g. an I/O operation, and cannot be run. Threads switch between these states and when they are ready the scheduler designates them a time slot on a CPU core to be executed. A naive scheduler would simply split the core's slot uniformly and give each runnable thread a similar share. For example, if the core's slot is 1s and there are 100 runnable threads, each thread would get 10ms of the core's computation time.
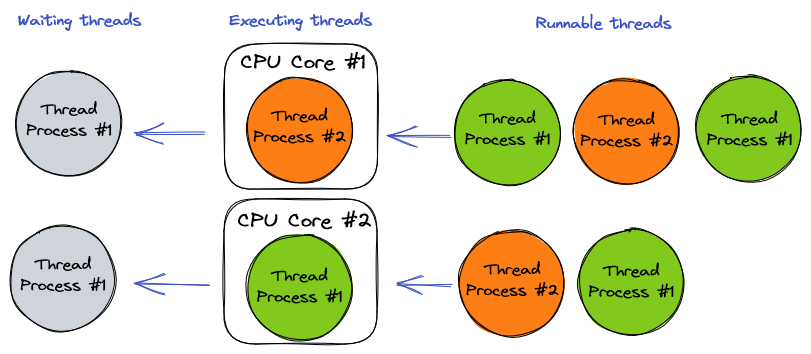
If there are threads to be run, the scheduler makes sure none of the cores would remain idle. The procedure in which the scheduler takes a thread off a CPU core and replaces another one to be executed is called a context switch. The point is, context switching is tremendously expensive. It's been said that each context switch takes the equivalent time of running a few thousand machine instructions.
Two types of threads exist. Some threads never encounter a point where they should wait for some system call or a request for network request to accomplish before they can go further and they are always runnable. The instruction sequence in these threads can push forward seamlessly and the only limit to how the fact they can execute is the computation power of the CPU. Therefore, they are called CPU-Bound threads. Naturally, there is another type of thread that is occasionally stopped for some IO tasks and cannot continue until those IO tasks are complete. That is to say, they get into the waiting state along the way and when they do, they are switched by the OS scheduler. These are called IO-Bound threads.
Normally, when performing concurrent tasks via a single process, employing multithreading would prompt the programming language's runtime to split the tasks into threads and let the OS manage the way they are executed. If the threads are IO-Bound, the scheduler's context switches would let them run almost in parallel and therefore there is a performance surge compared to a naive approach where the core would remain idle when a thread is waiting for an IO task. However, If this process has multiple threads over each core and all those threads are CPU-Bound, the ensuing context switches would result in the process's performance dropping drastically. That is why running simple CPU-Bound computations concurrently over a multitude of threads, say a million, is not a good idea.
The fact is, when the OS scheduler receives the threads, the context switching overhead is there regardless of the types of threads running. At the application level, there is a trade-off to be made between the context switching overhead and program's idle time through the number of threads. What makes context switching cost-effective is that the payoff, avoiding idle cores, is magnificent when IO-Bound threads are involved. More importantly, context switching would make different processes look like they are running in parallel. These make the overhead inevitable at the OS level.
But, what if we could mitigate such an overhead at the application level? Runtime has more control over the threads of an application. If one could exploit the privileges of runtime over its threads to perform context switches more efficiently, the overhead would drop and the performance would improve. The Go's runtime scheduler is apparently designed with the same mentality.
Go has introduced a new abstract layer over threads in its runtime to decouple ordered tasks, execution threads, from the OS threads. Go's conceptual model calls a logical CPU core a processor or a (P) and a thread a machine or an (M). Threads of execution are called Goroutine or (G) and they are different than (M)s. Go assigns every (P) an initial (M) and (G)s are distributed between (P)s for execution. In this model, as the OS scheduler performs context switching of threads over a CPU core, the Go scheduler performs context switching of goroutines over a host thread a.k.a (M).
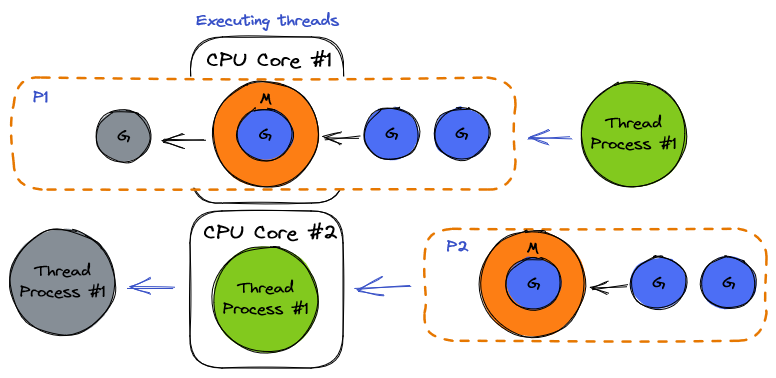
A lot is going on about what tricks the Go scheduler uses to perform context switching such as networking polling and asynchronous system calls and work stealing, which we are not going to discuss. But, the outcome is that the context switching of IO-Bound goroutines over a thread makes that thread look like CPU-Bound for the OS scheduler. From the OS's perspective, the program's threads, (M)s, always have work to do, even though these works are actually related to different goroutines. Since the Go scheduler's context switching is way cheaper than that of the OS, Go runtime has managed to minimize the overhead of the context Switch while making sure the program experiences the minimum possible idle time on each of the CPU cores. Consequently, Go gains performance by optimizing on a trade-off explained above.